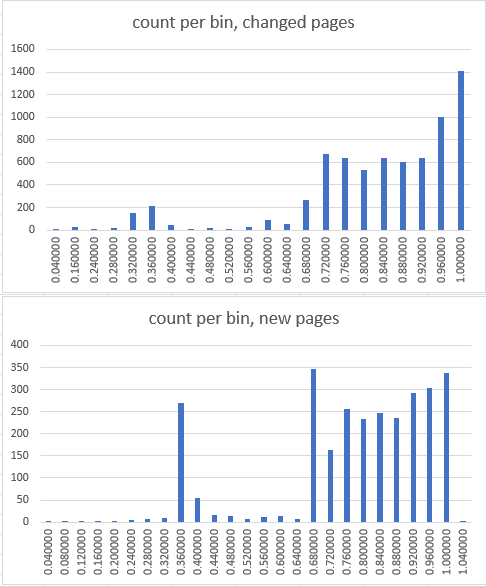
Thank you, the changed and new pages per bin (raw data below):
This is from a new experiment that is barely above the 4 GB optimization overhead, as I had to convert back to SSD due to the size growth. I even tried to backup, delete the FDB installation (as it was updated from 6.3 to 7.1), install 7.1 and restore. The size of raw data (k+v ) is reported as 6.3 GB.
After server restart:
<Event Severity="10" Time="1669196660.889803" DateTime="2022-11-23T09:44:20Z" Type="RedwoodRecoveredBTree" ID="0000000000000000" FileName="/var/lib/foundationdb/data/4500/storage-f87bfbd4641191514656a281b157560d.redwood-v1"
OpenedExisting="1"
LatestVersion="166473"
LazyClearQueueRecords="0"
LazyClearQueuePages="1"
LazyClearQueueRecordsPerPage="0"
ThreadID="11653865267480727846" Machine="127.0.0.1:4500" LogGroup="default" Roles="SS" />
<Event Severity="10" Time="1669196660.889803" DateTime="2022-11-23T09:44:20Z" Type="RedwoodRecoveredPager" ID="0000000000000000"
OpenedExisting="1" FileName="/var/lib/foundationdb/data/4500/storage-f87bfbd4641191514656a281b157560d.redwood-v1"
LogicalFileSize="13747232768"
PhysicalFileSize="13762560000"
CommittedVersion="166473"
LogicalPageSize="8192"
PhysicalPageSize="8192"
RemapQueueRecords="498249"
RemapQueuePages="1906"
RemapQueueRecordsPerPage="261.411"
FreeQueueRecords="2137"
FreeQueuePages="19"
FreeQueueRecordsPerPage="112.474"
DelayedFreeQueueRecords="81"
DelayedFreeQueuePages="2"
DelayedFreeQueueRecordsPerPage="40.5"
UsedExtentQueueRecords="2"
UsedExtentQueuePages="3"
UsedExtentQueueRecordsPerPage="0.666667"
FreeExtentQueueRecords="2"
FreeExtentQueuePages="3"
FreeExtentQueueRecordsPerPage="0.666667"
StorageBytesUsed="13728890880"
StorageBytesTemp="4081655808"
StorageBytesTotal="51835101184"
StorageBytesFree="31935422464"
StorageBytesAvailable="31953764352"
ThreadID="11653865267480727846" Machine="127.0.0.1:4500" LogGroup="default" Roles="SS" />
Raw data:
<Event Severity="10" Time="1669195789.951340" DateTime="2022-11-23T09:29:49Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30.0042" LessThan0.040000="1" LessThan0.160000="29" LessThan0.240000="3" LessThan0.280000="20" LessThan0.320000="151" LessThan0.360000="210" LessThan0.400000="43" LessThan0.440000="9" LessThan0.480000="22" LessThan0.520000="13" LessThan0.560000="29" LessThan0.600000="88" LessThan0.640000="51" LessThan0.680000="266" LessThan0.720000="675" LessThan0.760000="643" LessThan0.800000="533" LessThan0.840000="638" LessThan0.880000="599" LessThan0.920000="640" LessThan0.960000="999" LessThan1.000000="1405" TotalCount="7067" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195819.951355" DateTime="2022-11-23T09:30:19Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="1" LessThan0.160000="1" LessThan0.200000="19" LessThan0.240000="3" LessThan0.280000="18" LessThan0.320000="140" LessThan0.360000="173" LessThan0.400000="29" LessThan0.440000="11" LessThan0.480000="18" LessThan0.520000="16" LessThan0.560000="19" LessThan0.600000="81" LessThan0.640000="51" LessThan0.680000="266" LessThan0.720000="660" LessThan0.760000="596" LessThan0.800000="549" LessThan0.840000="586" LessThan0.880000="615" LessThan0.920000="565" LessThan0.960000="894" LessThan1.000000="1170" TotalCount="6481" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195849.951426" DateTime="2022-11-23T09:30:49Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30.0001" LessThan0.040000="1" LessThan0.160000="53" LessThan0.240000="8" LessThan0.280000="26" LessThan0.320000="159" LessThan0.360000="253" LessThan0.400000="35" LessThan0.440000="9" LessThan0.480000="17" LessThan0.520000="25" LessThan0.560000="15" LessThan0.600000="87" LessThan0.640000="56" LessThan0.680000="303" LessThan0.720000="717" LessThan0.760000="638" LessThan0.800000="661" LessThan0.840000="711" LessThan0.880000="726" LessThan0.920000="674" LessThan0.960000="1015" LessThan1.000000="1467" TotalCount="7656" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195879.951443" DateTime="2022-11-23T09:31:19Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="1" LessThan0.160000="2" LessThan0.240000="6" LessThan0.280000="21" LessThan0.320000="182" LessThan0.360000="145" LessThan0.400000="21" LessThan0.440000="15" LessThan0.480000="14" LessThan0.520000="23" LessThan0.560000="22" LessThan0.600000="88" LessThan0.640000="57" LessThan0.680000="269" LessThan0.720000="700" LessThan0.760000="659" LessThan0.800000="623" LessThan0.840000="707" LessThan0.880000="666" LessThan0.920000="696" LessThan0.960000="958" LessThan1.000000="1179" TotalCount="7054" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195909.952585" DateTime="2022-11-23T09:31:49Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30.0011" LessThan0.040000="1" LessThan0.120000="1" LessThan0.160000="1" LessThan0.240000="2" LessThan0.280000="21" LessThan0.320000="207" LessThan0.360000="231" LessThan0.400000="37" LessThan0.440000="13" LessThan0.480000="17" LessThan0.520000="21" LessThan0.560000="21" LessThan0.600000="91" LessThan0.640000="61" LessThan0.680000="296" LessThan0.720000="745" LessThan0.760000="658" LessThan0.800000="623" LessThan0.840000="692" LessThan0.880000="641" LessThan0.920000="608" LessThan0.960000="1022" LessThan1.000000="1412" TotalCount="7422" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195939.952603" DateTime="2022-11-23T09:32:19Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="1" LessThan0.160000="1" LessThan0.240000="2" LessThan0.280000="40" LessThan0.320000="173" LessThan0.360000="196" LessThan0.400000="37" LessThan0.440000="9" LessThan0.480000="16" LessThan0.520000="23" LessThan0.560000="10" LessThan0.600000="84" LessThan0.640000="58" LessThan0.680000="264" LessThan0.720000="538" LessThan0.760000="491" LessThan0.800000="505" LessThan0.840000="533" LessThan0.880000="535" LessThan0.920000="534" LessThan0.960000="827" LessThan1.000000="1118" TotalCount="5995" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195969.952622" DateTime="2022-11-23T09:32:49Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="2" LessThan0.160000="1" LessThan0.240000="2" LessThan0.280000="20" LessThan0.320000="170" LessThan0.360000="207" LessThan0.400000="48" LessThan0.440000="9" LessThan0.480000="19" LessThan0.520000="19" LessThan0.560000="30" LessThan0.600000="84" LessThan0.640000="57" LessThan0.680000="295" LessThan0.720000="722" LessThan0.760000="635" LessThan0.800000="563" LessThan0.840000="676" LessThan0.880000="708" LessThan0.920000="683" LessThan0.960000="1041" LessThan1.000000="1425" TotalCount="7416" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669195999.952729" DateTime="2022-11-23T09:33:19Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30.0001" LessThan0.040000="1" LessThan0.160000="1" LessThan0.240000="34" LessThan0.280000="17" LessThan0.320000="153" LessThan0.360000="160" LessThan0.400000="33" LessThan0.440000="6" LessThan0.480000="14" LessThan0.520000="17" LessThan0.560000="24" LessThan0.600000="80" LessThan0.640000="44" LessThan0.680000="257" LessThan0.720000="589" LessThan0.760000="549" LessThan0.800000="544" LessThan0.840000="539" LessThan0.880000="641" LessThan0.920000="576" LessThan0.960000="883" LessThan1.000000="1141" TotalCount="6303" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196029.954096" DateTime="2022-11-23T09:33:49Z" Type="Histogram" ID="0000000000000000" Group="modifyFillPct" Op="L1" Unit="percentage" Elapsed="30.0014" LessThan0.080000="1" LessThan0.200000="1" LessThan0.240000="7" LessThan0.280000="21" LessThan0.320000="210" LessThan0.360000="223" LessThan0.400000="45" LessThan0.440000="13" LessThan0.480000="16" LessThan0.520000="16" LessThan0.560000="24" LessThan0.600000="102" LessThan0.640000="52" LessThan0.680000="239" LessThan0.720000="606" LessThan0.760000="610" LessThan0.800000="509" LessThan0.840000="557" LessThan0.880000="620" LessThan0.920000="544" LessThan0.960000="874" LessThan1.000000="1334" TotalCount="6624" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196389.955369" DateTime="2022-11-23T09:39:49Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="2" LessThan0.080000="1" LessThan0.120000="3" LessThan0.160000="3" LessThan0.200000="2" LessThan0.240000="5" LessThan0.280000="7" LessThan0.320000="10" LessThan0.360000="270" LessThan0.400000="54" LessThan0.440000="17" LessThan0.480000="14" LessThan0.520000="7" LessThan0.560000="11" LessThan0.600000="15" LessThan0.640000="7" LessThan0.680000="347" LessThan0.720000="164" LessThan0.760000="255" LessThan0.800000="233" LessThan0.840000="248" LessThan0.880000="236" LessThan0.920000="293" LessThan0.960000="303" LessThan1.000000="338" LessThan1.040000="2" TotalCount="2847" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196419.956688" DateTime="2022-11-23T09:40:19Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30.0013" LessThan0.120000="1" LessThan0.200000="2" LessThan0.240000="3" LessThan0.280000="3" LessThan0.320000="12" LessThan0.360000="281" LessThan0.400000="65" LessThan0.440000="17" LessThan0.480000="19" LessThan0.520000="7" LessThan0.560000="8" LessThan0.600000="6" LessThan0.640000="13" LessThan0.680000="353" LessThan0.720000="190" LessThan0.760000="250" LessThan0.800000="246" LessThan0.840000="237" LessThan0.880000="255" LessThan0.920000="277" LessThan0.960000="284" LessThan1.000000="315" LessThan1.040000="1" TotalCount="2845" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196449.956706" DateTime="2022-11-23T09:40:49Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="3" LessThan0.080000="3" LessThan0.120000="3" LessThan0.160000="3" LessThan0.200000="6" LessThan0.240000="3" LessThan0.280000="4" LessThan0.320000="19" LessThan0.360000="239" LessThan0.400000="67" LessThan0.440000="11" LessThan0.480000="17" LessThan0.520000="7" LessThan0.560000="10" LessThan0.600000="12" LessThan0.640000="4" LessThan0.680000="310" LessThan0.720000="196" LessThan0.760000="261" LessThan0.800000="234" LessThan0.840000="244" LessThan0.880000="271" LessThan0.920000="283" LessThan0.960000="263" LessThan1.000000="327" TotalCount="2800" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196479.956742" DateTime="2022-11-23T09:41:19Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="1" LessThan0.080000="3" LessThan0.120000="1" LessThan0.160000="3" LessThan0.200000="1" LessThan0.240000="3" LessThan0.280000="5" LessThan0.320000="13" LessThan0.360000="260" LessThan0.400000="82" LessThan0.440000="7" LessThan0.480000="19" LessThan0.520000="6" LessThan0.560000="11" LessThan0.600000="10" LessThan0.640000="13" LessThan0.680000="354" LessThan0.720000="155" LessThan0.760000="233" LessThan0.800000="300" LessThan0.840000="257" LessThan0.880000="252" LessThan0.920000="259" LessThan0.960000="285" LessThan1.000000="347" TotalCount="2880" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196509.956984" DateTime="2022-11-23T09:41:49Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30.0002" LessThan0.040000="2" LessThan0.080000="2" LessThan0.120000="1" LessThan0.160000="2" LessThan0.200000="4" LessThan0.240000="5" LessThan0.280000="7" LessThan0.320000="19" LessThan0.360000="246" LessThan0.400000="73" LessThan0.440000="12" LessThan0.480000="17" LessThan0.520000="6" LessThan0.560000="8" LessThan0.600000="6" LessThan0.640000="3" LessThan0.680000="328" LessThan0.720000="180" LessThan0.760000="251" LessThan0.800000="272" LessThan0.840000="252" LessThan0.880000="258" LessThan0.920000="278" LessThan0.960000="277" LessThan1.000000="335" LessThan1.040000="1" TotalCount="2845" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />
<Event Severity="10" Time="1669196539.957032" DateTime="2022-11-23T09:42:19Z" Type="Histogram" ID="0000000000000000" Group="buildFillPct" Op="L1" Unit="percentage" Elapsed="30" LessThan0.040000="1" LessThan0.080000="1" LessThan0.120000="2" LessThan0.160000="1" LessThan0.200000="1" LessThan0.240000="1" LessThan0.280000="4" LessThan0.320000="13" LessThan0.360000="289" LessThan0.400000="64" LessThan0.440000="7" LessThan0.480000="16" LessThan0.520000="5" LessThan0.560000="11" LessThan0.600000="8" LessThan0.640000="5" LessThan0.680000="360" LessThan0.720000="191" LessThan0.760000="233" LessThan0.800000="235" LessThan0.840000="229" LessThan0.880000="274" LessThan0.920000="269" LessThan0.960000="304" LessThan1.000000="322" LessThan1.040000="1" TotalCount="2847" ThreadID="2558203997968097348" Machine="127.0.0.1:4500" LogGroup="default" Roles="CC,CD,CP,DD,GP,MS,RK,RV,SS,TL" />