fdb test env on ec2
storage process: 12
transaction process: 5
stateless process: 10
Redundancy mode: triple
storage engine ssd
version: 7.1.0
We use mako to do benchmark, mostly write tests.
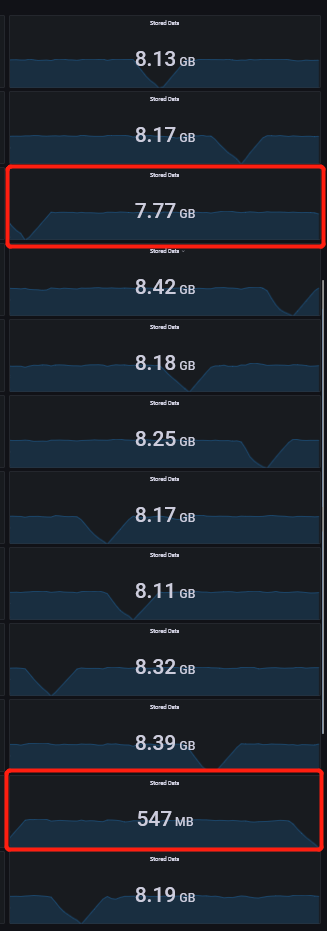
Then we find something wired about rebalancing, fdb keep rebalancing even if we stop the test.
As I understandb, if there are 120G data, for 12 storage processes, each storage process should store 10G data, data volume should be more or less the same.
But for our production env, only two storage process do the “rebalance”, “rebalance” means the first storage process moves almost all datas to the second storage process, then the second storage process moves datas back to the the first storage process, like a endless loop…
fdb> status details
Using cluster file `/etc/foundationdb/fdb.cluster'.
Configuration:
Redundancy mode - triple
Storage engine - ssd-2
Coordinators - 5
Desired Logs - 5
Usable Regions - 1
Cluster:
FoundationDB processes - 27
Zones - 16
Machines - 16
Memory availability - 7.3 GB per process on machine with least available
Retransmissions rate - 0 Hz
Fault Tolerance - 2 machines
Server time - 08/01/22 10:34:29
Data:
Replication health - Healthy (Rebalancing)
Moving data - 7.174 GB
Sum of key-value sizes - 29.963 GB
Disk space used - 109.617 GB
Storage wiggle:
Wiggle server addresses- 10.5.120.55:4500
Wiggle server count - 1
Operating space:
Storage server - 454.1 GB free on most full server
Log server - 82.7 GB free on most full server
Workload:
Read rate - 104 Hz
Write rate - 9 Hz
Transactions started - 23 Hz
Transactions committed - 1 Hz
Conflict rate - 0 Hz
Backup and DR:
Running backups - 0
Running DRs - 0
Process performance details:
10.5.120.44:4500 ( 0% cpu; 1% machine; 0.000 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.44:4501 ( 1% cpu; 1% machine; 0.000 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.45:4500 ( 2% cpu; 1% machine; 0.002 Gbps; 0% disk IO; 0.2 GB / 7.3 GB RAM )
10.5.120.45:4501 ( 1% cpu; 1% machine; 0.002 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.46:4500 ( 2% cpu; 1% machine; 0.022 Gbps; 7% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.46:4501 ( 1% cpu; 1% machine; 0.022 Gbps; 4% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.47:4500 ( 1% cpu; 3% machine; 0.001 Gbps; 6% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.47:4501 ( 11% cpu; 3% machine; 0.001 Gbps; 8% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.48:4500 ( 1% cpu; 1% machine; 0.000 Gbps; 2% disk IO; 2.0 GB / 8.0 GB RAM )
10.5.120.49:4500 ( 1% cpu; 1% machine; 0.000 Gbps; 9% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.49:4501 ( 5% cpu; 1% machine; 0.000 Gbps; 8% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.50:4500 ( 1% cpu; 1% machine; 0.000 Gbps; 2% disk IO; 2.0 GB / 8.0 GB RAM )
10.5.120.51:4500 ( 1% cpu; 2% machine; 0.041 Gbps; 21% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.51:4501 ( 4% cpu; 2% machine; 0.041 Gbps; 20% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.52:4500 ( 3% cpu; 2% machine; 0.001 Gbps; 19% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.52:4501 ( 2% cpu; 2% machine; 0.001 Gbps; 20% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.53:4500 ( 1% cpu; 1% machine; 0.001 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.53:4501 ( 1% cpu; 1% machine; 0.001 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.54:4500 ( 2% cpu; 1% machine; 0.003 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.54:4501 ( 1% cpu; 1% machine; 0.003 Gbps; 0% disk IO; 0.1 GB / 7.3 GB RAM )
10.5.120.55:4500 ( 5% cpu; 3% machine; 0.023 Gbps; 37% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.55:4501 ( 7% cpu; 3% machine; 0.023 Gbps; 34% disk IO;13.5 GB / 14.0 GB RAM )
10.5.120.56:4500 ( 1% cpu; 0% machine; 0.000 Gbps; 1% disk IO; 2.0 GB / 8.0 GB RAM )
10.5.120.57:4500 ( 1% cpu; 1% machine; 0.000 Gbps; 2% disk IO; 2.0 GB / 8.0 GB RAM )
10.5.120.58:4500 ( 1% cpu; 0% machine; 0.000 Gbps; 0% disk IO; 0.7 GB / 7.4 GB RAM )
10.5.120.58:4501 ( 1% cpu; 0% machine; 0.000 Gbps; 0% disk IO; 0.1 GB / 7.4 GB RAM )
10.5.120.59:4500 ( 1% cpu; 1% machine; 0.000 Gbps; 2% disk IO; 2.0 GB / 8.0 GB RAM )
Coordination servers:
10.5.120.46:4500 (reachable)
10.5.120.47:4500 (reachable)
10.5.120.49:4500 (reachable)
10.5.120.51:4500 (reachable)
10.5.120.55:4500 (reachable)
Client time: 08/01/22 10:34:29