In our FDB deployment environment, we choose the 3-DC asymmetric configuration recommended in the FDB architecture document. DC1 is the primary, DC2 holds the transactional logs to support HA, and DC3 is the secondary. In our monthly OS maintenance, all VMs in each of DC1, DC2 and DC3 need to go through security patching in phases, with each phase only having one DC to be patched.
If patching host machines one by one, it would lead to multiple VMs being down and up and thus introduce frequent cluster-wide data rebalancing. Instead, when we patch DC1 (similar to DC3), we perform the following steps:
- The whole FDB cluster is configured to run only in DC3 (that is, the single-DC mode), and then shutdown DC1 so that the VMs in DC1 can go through security patching.
- When DC1’s patching finishes, we re-active DC1’s VMs and thus the FDB processes. So that the whole FDB cluster is back to the two-DC mode, with DC3 being the primary.
- At this time, data synchronization between DC1 and DC3 happens, because of changing from one-DC mode to 2-DC mode. We wait until data synchronization finishes.
- The FDB cluster is configured to have DC1 to be the primary DC and DC3 to be the secondary DC.
When we perform the DC patching, we turn off the writes to the FDB cluster and only allow the reads to go through. We turn on writes again after Step 4 finishes. To monitor how data synchronization progresses, we extract the following two metrics exported from the FDB’s status.json file:
- Moving Data In-Flight
- Moving Data In-Queue
In the status.json file retrieved from FDB, these two metrics are at:
“cluster” : {
“data” : {
"moving_data": {
"in_flight_bytes": *,
"in_queue_bytes": *,
},
}
}
In a recent testing, at Step 3, we observed the following behavior for “moving data in-flight”:

The above plot shows the time duration from 22:32 pm to 1:52 am, totally 3 hours 20 minutes. The peak happened almost instantaneously after DC1’s VMs recovered from patching, but it took such a long time for data to be synchronized and still at the end, at 1:52 am, 4.1 GB was reported for moving data in-flight.
And the plot for “moving data in-queue” is the following:

Like moving data in-flight, the peak of data to be-moved in queue, 5.0 TB, happens after DC1’s VMs recovered from patching, at around 22:30 pm, and in fact, the maximum total amount of reported moving data in-queue is the total amount of data stored in the key/value store (one data copy). Note that the above curve does show the gradual decay of moving data in-queue. Visually, at 00:20 am, that is, 2 hours after switching from one-DC mode to two-DC mode, the moving data in-queue was completed. But if we pick some time segment, from example, from 1:05 am to 1:20 am, we can still some local peak as shown below:
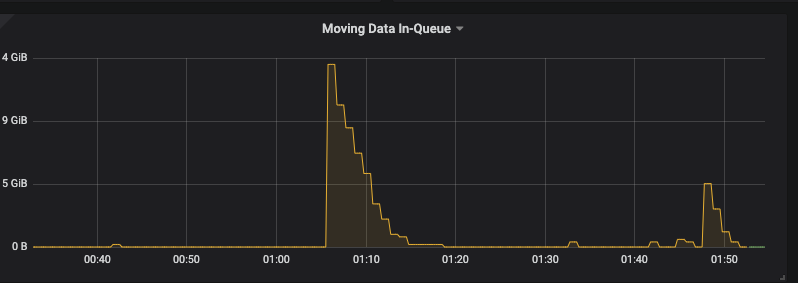
But the local peak of 14 GB, compared to the global peak of moving data in-queue of 5.0 TB, is negligible.
I am aware that the FDB cluster constantly performs data re-balancing and re-partitioning, and it happens in the background. Still we like to reduce the impact of data re-balancing to our real-time read/write traffic. Specific to the situation that we have on datacenter patching related maintenance, during the entire patching duration, we purposely stop the write traffic to avoid large data synchronization. I believe that data re-balancing happens due to the switching from the state in which DC3 being a single datacenter holding the data, to the state in which DC1 and DC3 both holding data. In fact, DC1, after being patched and then turned on, should have almost exact data copies to DC3, as we do not have writes during the patching period.
My questions related to data synchronization are the following:
- What do “moving data in flight” and “moving data in queue” really mean? What is the difference between these two metrics?
- What would be the criteria to safely identify the time when data synchronization is finished, due to datacenter configuration switching? It seems that if we choose “moving data in-queue”, the detection is much easier, based on the above plots related to “moving data in-queue”. But what about “moving data in-flight”, what can it tell us about? And should we also rely on “moving data in-flight” to determine when data synchronization finishes?
- What would be other good indicators from the reported FDB status.json that can help detect that data synchronization is finished?