I’ve been helping Ray debug this. We’ve managed to simplify the problem considerably. We can reproduce it by writing fully random keys (no reads, no prefixes) at a high rate (saturating FDB, so about ~50-100kps) for about 6-7 minutes. Following that, FoundationDB’s log queue size spikes, storage queue size diverges (different processes having wildly different sizes), and throughput drops.
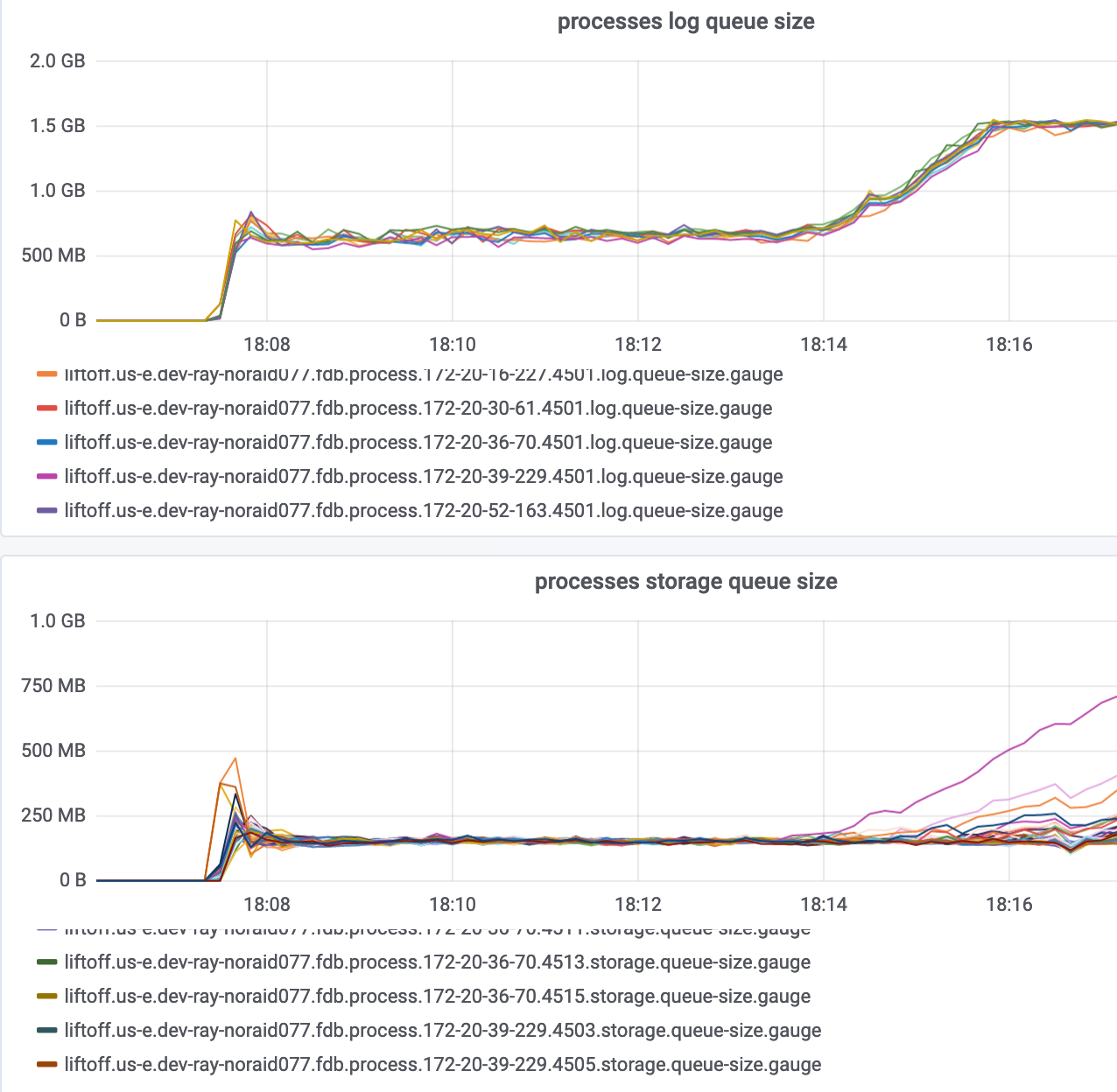
Here’s an example with 10 i3.16xlarge instances running at 3x redundancy.

Here’s 3 i3.16xlarge instances running at 1x redundancy. (A single instance had its log queue instantly maxed out, which didn’t allow us to demonstrate this odd divergence behavior).

Here’s 10 i3.16x large instances running at 1x redundancy. This is stable, suggesting that the problems we’re observing have something to do with the ratio of total machine/disk count to workload. However, I still don’t fully understand what’s happening.
My current best guess is that there’s some kind of cleanup or other secondary work being done after that 6-7 minute mark, which causes the load on the log processes to exceed its handling capacity. I’m not clear on what that would be, however.
Any feedback would be enormously appreciated.